Microsoft Navision ERP es una potente herramienta que automatiza y optimiza una amplia gama de procesos comerciales. Abarcando áreas como finanzas, ventas, operaciones, cuentas de compras e inventario. Este sistema también se destaca como un repositorio central de datos operativos para equipos y la alta dirección. Permitiendo a las empresas gestionar pedidos de envío directo y mantener un directorio de proveedores. Al mismo tiempo, optimiza la capacidad de fabricación y la asignación de recursos.
La versatilidad de este software ERP se evidencia en su capacidad para adaptarse a los requisitos específicos de diferentes tipos de empresas. Las organizaciones que implementan este sistema pueden gestionar eficazmente las finanzas y las operaciones de la cadena de suministro desde una ubicación centralizada. Esto se traduce en la capacidad de tomar decisiones más informadas y aprovechar rápidamente las oportunidades de mercado, lo que permite a las empresas alcanzar sus objetivos de manera más eficiente.
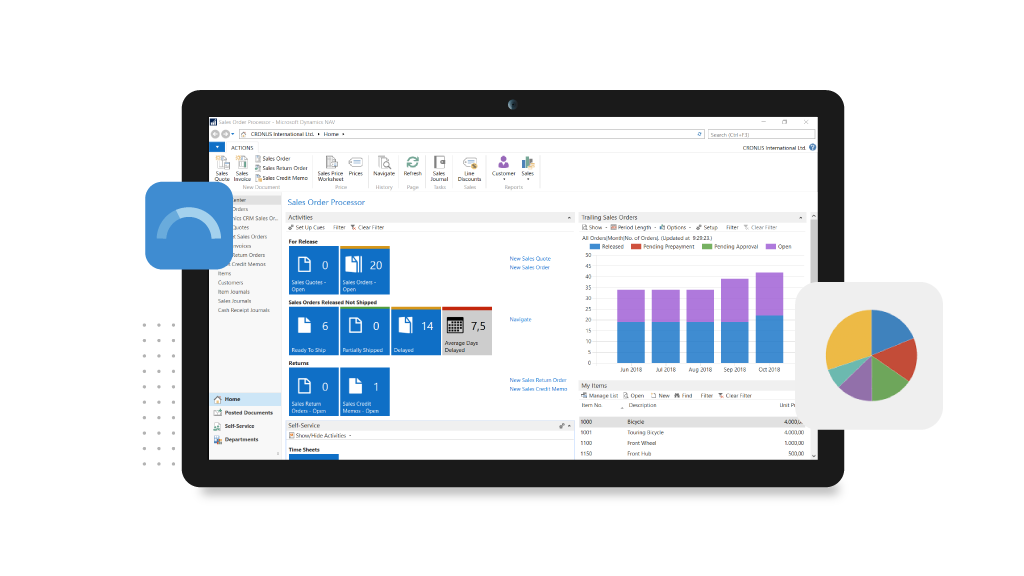
La facilidad de uso de este software, así como su capacidad de adaptación a las necesidades únicas de cada negocio, se atribuye en parte a su solución de inteligencia empresarial integrada. Esto permite a los usuarios tomar decisiones basadas en datos sólidos y cifras, con acceso a indicadores clave de rendimiento y tendencias financieras en tiempo real. Además, los usuarios pueden aprovechar la aplicación Power BI para crear informes personalizados y paneles de control.
La implementación de un sistema ERP como Navision no solo puede reducir costos, sino que también aumenta los ingresos al automatizar tareas y mejorar la productividad. También mejora el servicio al cliente al permitir que los empleados respondan de manera más eficiente a las consultas y solicitudes de los clientes.
Es fundamental elegir una solución ERP que se adapte a las necesidades comerciales específicas de la empresa
Microsoft Dynamics NAV (anteriormente Navision ERP) es un sistema de planificación de recursos empresariales basado en la nube que ofrece una amplia gama de funciones, incluyendo contabilidad, gestión de inventario, proyectos, servicios y CRM. Esta solución es adecuada para pequeñas y medianas empresas en diversas industrias y ofrece soporte multilingüe, así como opciones de implementación flexibles que incluyen la nube privada, local y el alojamiento de Azure. Su base de datos escalable permite el crecimiento y la interoperabilidad con aplicaciones de terceros.
A pesar de su relativa juventud, Navision ERP sigue siendo una de las soluciones empresariales más utilizadas en el mercado. Inicialmente desarrollado en 1984 como software de PC para el seguimiento de finanzas, débitos y créditos, fue adquirido por Microsoft y rebautizado como Microsoft Dynamics NAV en 2005 para satisfacer las demandas comerciales en constante crecimiento.
Microsoft Navision ERP brinda a las empresas la capacidad de optimizar y consolidar sus procesos, mejorar la interacción con los clientes y tomar decisiones más acertadas. Al mantener todos los datos relacionados con la empresa en un solo lugar, elimina redundancias y garantiza el acceso a información actualizada para todo el equipo. Esto se traduce en una mayor rentabilidad, una mayor precisión de los registros y menores gastos operativos al proporcionar una visión precisa de las finanzas de la empresa.
Este sistema ERP líder en la industria se adapta a múltiples departamentos en una sola plataforma
Ya sea implementado en la nube o en las instalaciones de la empresa. Permite a las empresas gestionar eficazmente el inventario, la fabricación, la contabilidad, las finanzas, la gestión de proyectos y el servicio al cliente. Además, ofrece funciones que facilitan el seguimiento de pedidos de clientes y la generación de pronósticos de inventario precisos. La automatización de flujos de trabajo mejora la eficiencia del servicio al cliente y la capacidad de respuesta ante las consultas de los clientes.
Navision ERP se destaca al ofrecer capacidades ERP y un sistema CRM integral que ayuda a las empresas a gestionar contactos y establecer relaciones con clientes potenciales. Además, se integra sin problemas con otras aplicaciones empresariales, como Microsoft Excel, lo que facilita la creación de informes personalizados y paneles de control. Esta solución es ideal para pequeñas y medianas empresas que buscan expandir sus operaciones.
Microsoft Dynamics es un conjunto en constante evolución que incluye software CRM, ERP y BI. Aunque su nombre ha cambiado, sus funciones se han mantenido consistentes. Microsoft lanzó varias versiones heredadas de la suite Dynamics 365 Business Central en 2016.
Microsoft Dynamics NAV ERP es una solución de gestión empresarial diseñada para ayudar a las empresas a administrar inventario, ventas y cuentas en una única base de datos. Este software simplifica las operaciones, reduce costos generales y mejora la rentabilidad al optimizar la colaboración, la planificación y la toma de decisiones.

La implementación de un sistema ERP puede ser un desafío complejo que requiere la experiencia de un socio experimentado para garantizar el éxito
El éxito de la implementación de ERP depende de una profunda comprensión de las políticas y procesos comerciales actuales, con la ayuda de un experto externo que puede identificar áreas de mejora y diseñar un plan general del proyecto. La realización de pruebas piloto permite probar la funcionalidad antes de implementar el sistema final, y contar con expertos a bordo garantiza un funcionamiento óptimo y sin obstáculos.
Un ERP puede simplificar los sistemas operativos de la empresa. Desde la fabricación y las ventas hasta las compras y la contabilidad, además de automatizar procesos y mejorar la gestión de datos. Algunos ERP también se integran con otras aplicaciones empresariales, como el comercio electrónico y las soluciones CRM, para una mayor eficiencia.
Antes, los ERP estaban diseñados para industrias específicas, pero hoy en día la mayoría puede adaptarse a múltiples sectores y funcionar tanto localmente como en la nube, lo que brinda a las empresas opciones para seleccionar un ERP que se ajuste a sus necesidades y presupuesto.
Los ERP ofrecen una serie de ventajas para las empresas en crecimiento, como una mayor precisión en el mantenimiento de registros, una mejora en el servicio al cliente y una visión más clara de las finanzas. Facilitan la comunicación eficiente entre departamentos, lo que brinda a las empresas una ventaja competitiva. Microsoft Navision ERP es una solución empresarial integral diseñada para manejar eficazmente los procesos financieros, operativos y de gestión de la empresa, con la flexibilidad necesaria para adaptarse a las cambiantes necesidades comerciales



